
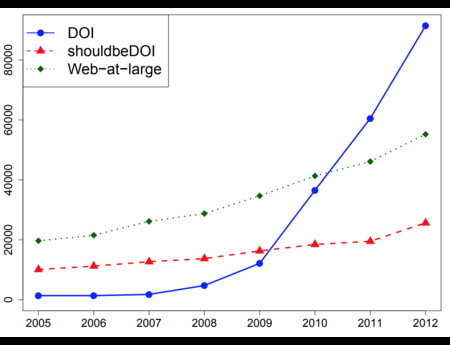
Symposium on Saving The Web at the Library of Congress

On June 16, 2016, the Library of Congress hosted a one day Symposium entitled Saving the Web: The Ethics and Challenges of Preserving What’s on the Internet.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}