
Web Science 2017 Trip Report

I was fortunate enough to have the opportunity to present Yasmin AlNoamany’s work at Web Science 2017. Dr. Nelson offers an excellent class on Web Science, but it has been years since I had taken it and I still was uncertain about the current state of the art. Web Science 2017...
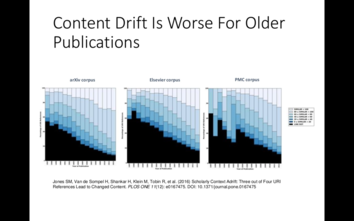
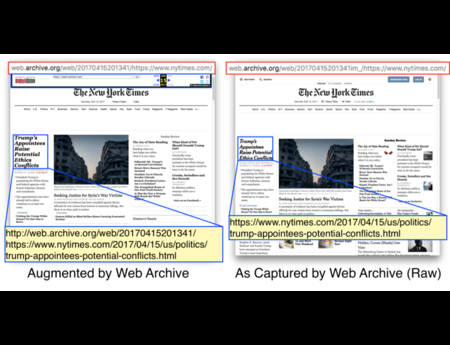

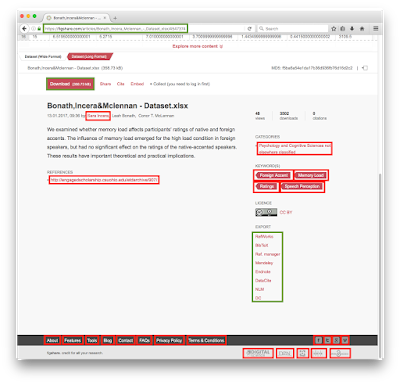
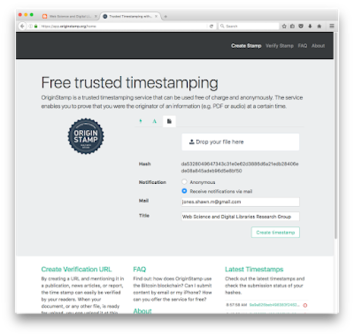
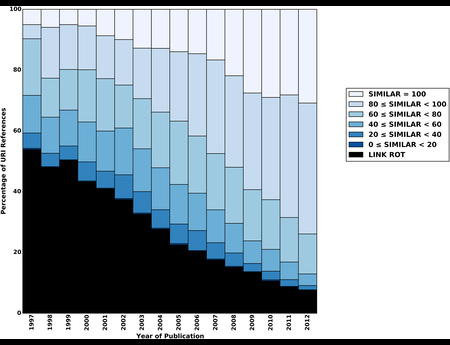


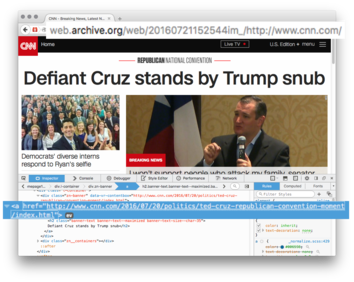
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}